How to write Makefile
about Makefile
When use golang development, almost use Makefile. Used by build and run go application.but I don't understand this format. So, I explain structure of Makefile.
title of process:
process
this command is minimum. other how to.
hoge: (depend on file or method)
process
call another title of process. it's capable chain process. and this is very important. next, wirte to process.
hoge: chmod 777
this simple. write shell command. use combination call method. these basic Makefile usage. almost build.
Swagger is the great tool
Use swagger when make open api
Use swagger in work project. I feel is great tool at openapi.
First, when I made the new api at current project.
Make dummy response api, its client side develop efficient.
We have many new develop points. its not better stop development.
the swagger in the local develop
Second, I develop api in docker. swagger UI is very easy access respectively api.
Add bearer token to header. and parameter. json response is easy to see. watch both response dummy and this.
I get efficient develop environment.
openapi definition
Openapi is the standard RESTful api. but make yaml definition is bothersome.
This tool solution these problem.
I think its effective to many developer relation project.
Request method definition yaml file. GET, POST and others.
I want use from now on. when use RESTful api.
Spannerを使ってみて大体の感想
久しぶりの更新になります。今回はGCPのCloudSpannerについてです。
決してサボっていた訳ではありません。仕事が・・・というよくあるやつです。
CloudSpannerとは
GCPが誇る分散型データベースです。
なんと言っても最大の特徴は、ノードを増やすことでスループットをリニアに向上させることが出来ることです。
ここで「ん?」と思った方もいるかもしれません。
そう、スケールを無停止で出来るデータベースはDynamoDBとかが既に存在しています。
ではSpannerは何がすごいのかと言うと、RDBでこれを実現した事です。
オートスケールなDBって基本的にNoSQLなんですよね。KVSとか。
でもSpannerはデータ構造はRDBのままです。なので既存のアプリケーションから移行しやすかったり、エンジニアも開発しやすかったりします。
ただ、全てが同じという訳ではなく、独特の構造上の制限があるので、そこを意識しないといけません。
逆に言うと、ポイントさえ押さえればスケール出来るRDBという武器が手に入るんですけどね。
Spannerのしくみ
まず一般的なDBだとこういう構造になると思います。(図はAuroraで考えています)
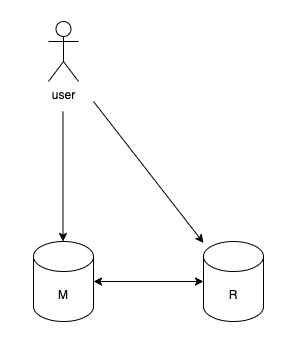
エンドポイント経由でマスターにWriteを行い、ROに読み込みにいき、バイナリログを送る事で同期する
フェイルオーバー時にマスターと入れ替わるという、ごく一般的な構造のDBです。
これの問題はデータのWriteがマスターにしかできないことですが、これはRDBの構造を考えれば、ごく当たり前の事です。
テーブル同士の密接な関係にあるので、1箇所に保存するしかないからです。
しかしSpannerはこれを下記のようにすることで問題をクリアしています。
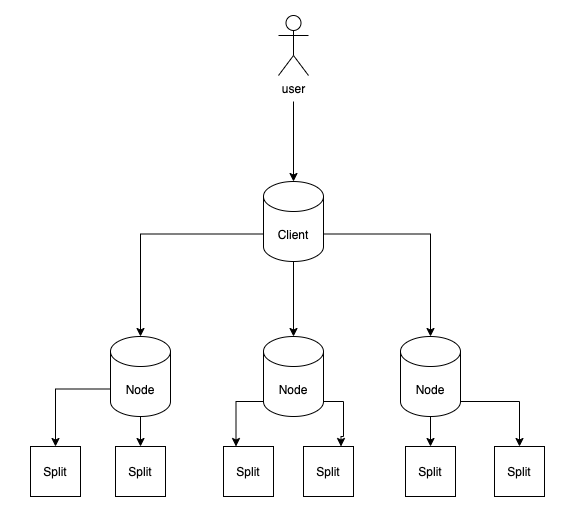
まずRead/Writeなどの情報はClientが一括して受け持ちます。
一つのSpannerインスタンスに一つのClientが存在しており、完全マネージドで動いています。なので普段これを意識することはありません。
次にノードという、実際の処理を行う基盤があります。
更にノードの紐付けされているsplitという実データが保存されているものが複数に分かれている構造になっています。
これがspannerの肝となる構造で、split単位で保存するからこそ、分散型DBとして機能しているのです。
split構造と注意点
一つのsplitは一つのノードに紐付けされており、図のように複数のsplitをノードは管理しています。
splitがどのように分割されて保存されるかはユーザー側は知り得る事はありません。自動的に保存先が割り振られます。
ただ近いPK同士は同じsplitに保存されるようで、この仕組み上、PKをauto incrementなどで連番で発番すると負荷が一つのノードに集中してしまいます。
これを防ぐ為に、PKはUUIDを使う事がスタンダードなやり方です。
ランダムにすることで保存先splitを分散させているんですね。
インターリーブ
spannerはjoinを使ってテーブル結合を行う事が出来ません。その代わりにインターリーブという機能があります。
これは他テーブルのカラムを自テーブルに取り込む機能で、同じsplit内に保存されるようになります。
分散型とはあえて逆をいく局所的な保存をすることで、無駄に他splitにデータが分散されてパフォーマンス劣化する事を抑えている形になります。